
Hybrid Infrastructure — Local LLM + API
We run a two-tier model architecture. Simple, repetitive tasks go to a local Ollama instance (qwen3:8b). Complex reasoning, code generation, and design work go to API models (Claude, DeepSeek). Each agent picks the model best suited to the task.
Why hybrid? Local inference costs next to nothing for high-volume, low-complexity work. API calls bring advanced capability exactly when it's needed. The Coder profile talks to Claude Code over the API for development work, while routine classification, summarization, and data extraction run locally — balancing token efficiency with quality.
Core idea: match the right model to the task — not the other way around.
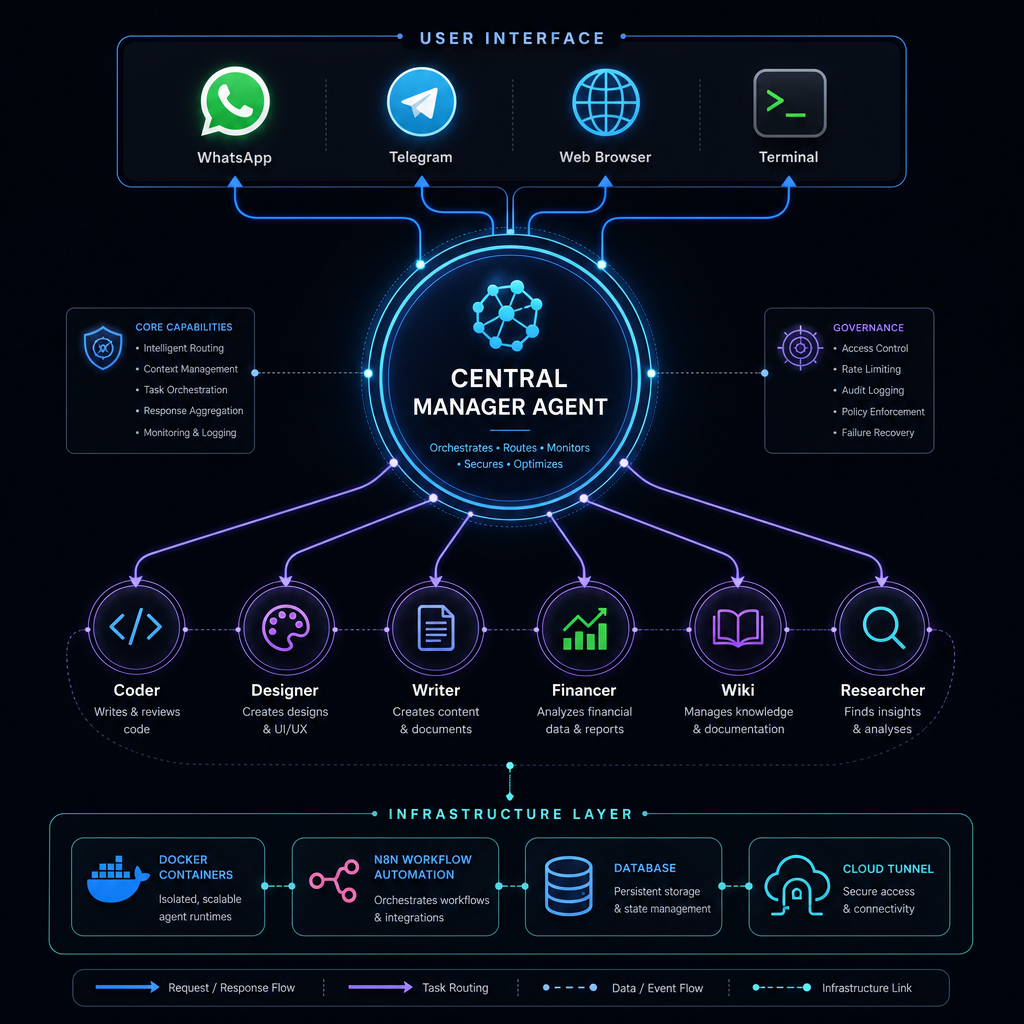
Example: Our Financer agent scans markets daily using local inference, only calling the API when a deep analysis report is required.
Hermes Multi-Agent System
Built on the Hermes Agent framework, our system runs 6 profiles — each with its own identity, skill set, and decision-making authority. The Manager Agent routes incoming requests to the right specialist: development to Coder, visuals to Designer, documents to Writer, market data to Financer, knowledge management to Wiki.
Each profile carries a SOUL.md — its personality file — defining language rules, available skills, constraints, and timezone. Agents decide for themselves which skills to load for a given task. The Manager doesn't micromanage. It just splits the work, assigns it, and merges the results.
Example: A request to "write a technical comparison of EAP-TLS authentication" is decomposed by the Manager → Writer researches and drafts → Designer creates diagrams → Coder assembles the final output. See the result: the EAP-TLS video presentation
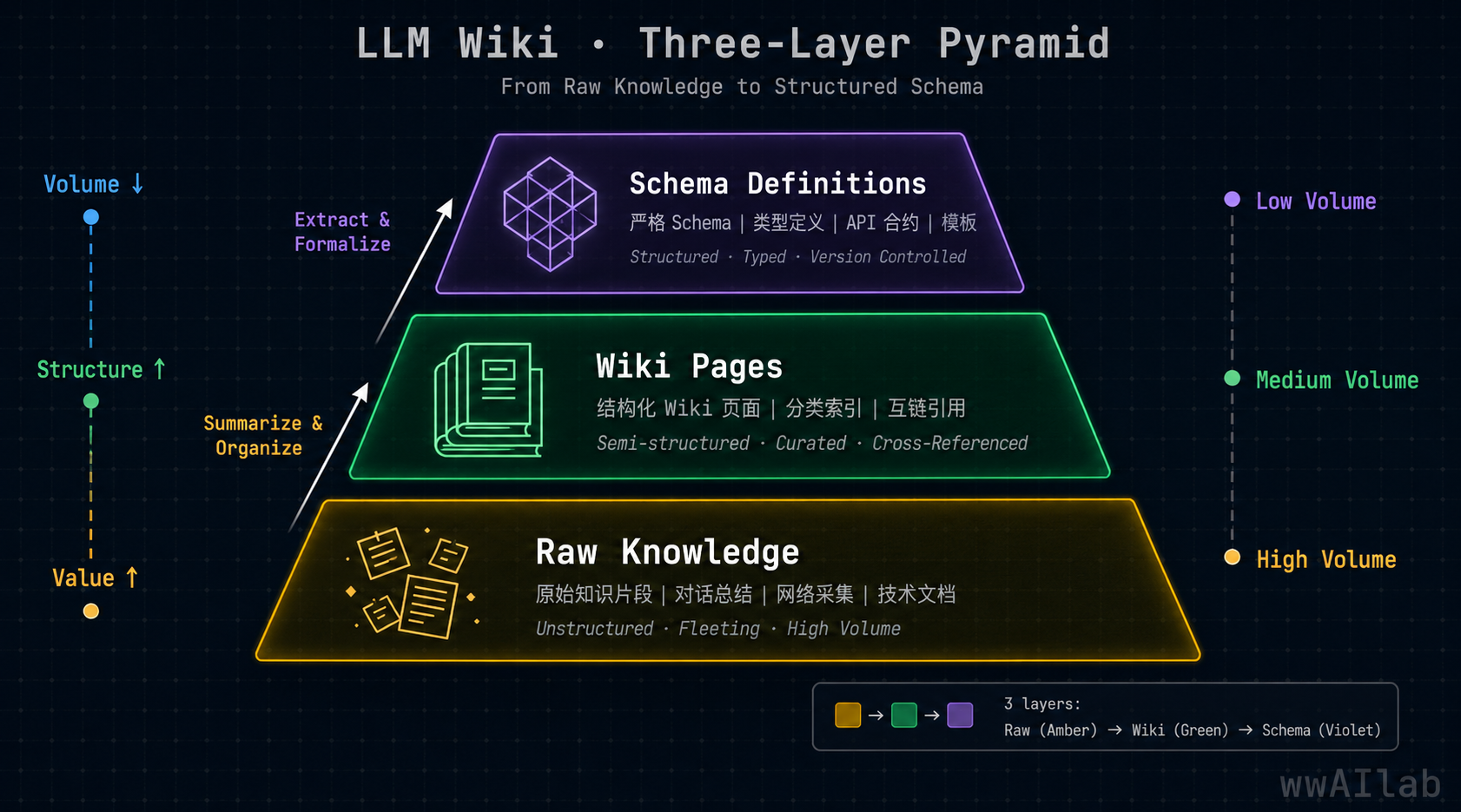
Local LLM Wiki (Karpathy Pattern)
We maintain a three-layer knowledge base, inspired by Andrej Karpathy's LLM Wiki concept.
raw/ ← immutable source data (chat logs, imports, notes) wiki/ ← compiled, interlinked knowledge pages (queryable, cross-referenced) schemas/ ← rules and operating guides
A dedicated Wiki Agent watches for changes, compiles new content into the wiki, and maintains [[wikilinks]] between pages. Unlike traditional RAG (which retrieves flat chunks at query time), our wiki pre-compiles knowledge at the ingestion stage. That brings faster retrieval, better cross-referencing, and dramatically lower token usage per query.
The result: persistent memory across sessions. A conversation from weeks ago can provide context for today's response — without re-ingesting the same data.
Further reading: Agent Skills vs MCP vs RAG — our comparison
Communication Channels — WhatsApp, Telegram, Slack, Voice
We believe AI should show up where people already are. The system supports:
- WhatsApp Bridge — Node.js (Baileys library), session-based, auto-reconnect
- Telegram Bot — lightweight, fast, reliable
- Slack — integrated via MCP server
- Voice — F5-TTS for speech output, Whisper.cpp for speech-to-text
This isn't about building yet another chat UI. It's about letting people collaborate with AI inside the tools they use every day. Send a voice memo on the road, get a written report back. Ask a question in Slack, get an answer with cited sources.
Further reading: WhatsApp Voice Video — how the voice channel works end-to-end
Custom Skills — Every Agent Has Its Own Toolbox
Each profile is equipped with a curated set of skills. Not one giant monolith, but modular, interchangeable capabilities:
| Profile | Example skills |
|---|---|
| Coder | Python/JS/TS toolchain, Playwright, Docker, git |
| Designer | GPT Image 2 generation, web design, video presentations |
| Writer | Technical docs, blog writing, copy editing |
| Financer | Stock analysis, Alpha Vantage API, market reports |
| Wiki | Knowledge compilation, link management, health checks |
| Manager | Task decomposition, delegation, result merging |
For repetitive tasks, we write scripts — not agent prompts. Scripts run with minimal token overhead. No LLM memory consumed, no KV cache polluted. Pure execution. This is the heart of our token-efficiency approach: don't waste context on things that don't require reasoning.
Skills in action: Web-video skill — EAP-TLS video | Web-documentation skill — Agent Skills vs MCP vs RAG
Example: A custom investment-report skill that produces a daily investment summary without loading a full agent.
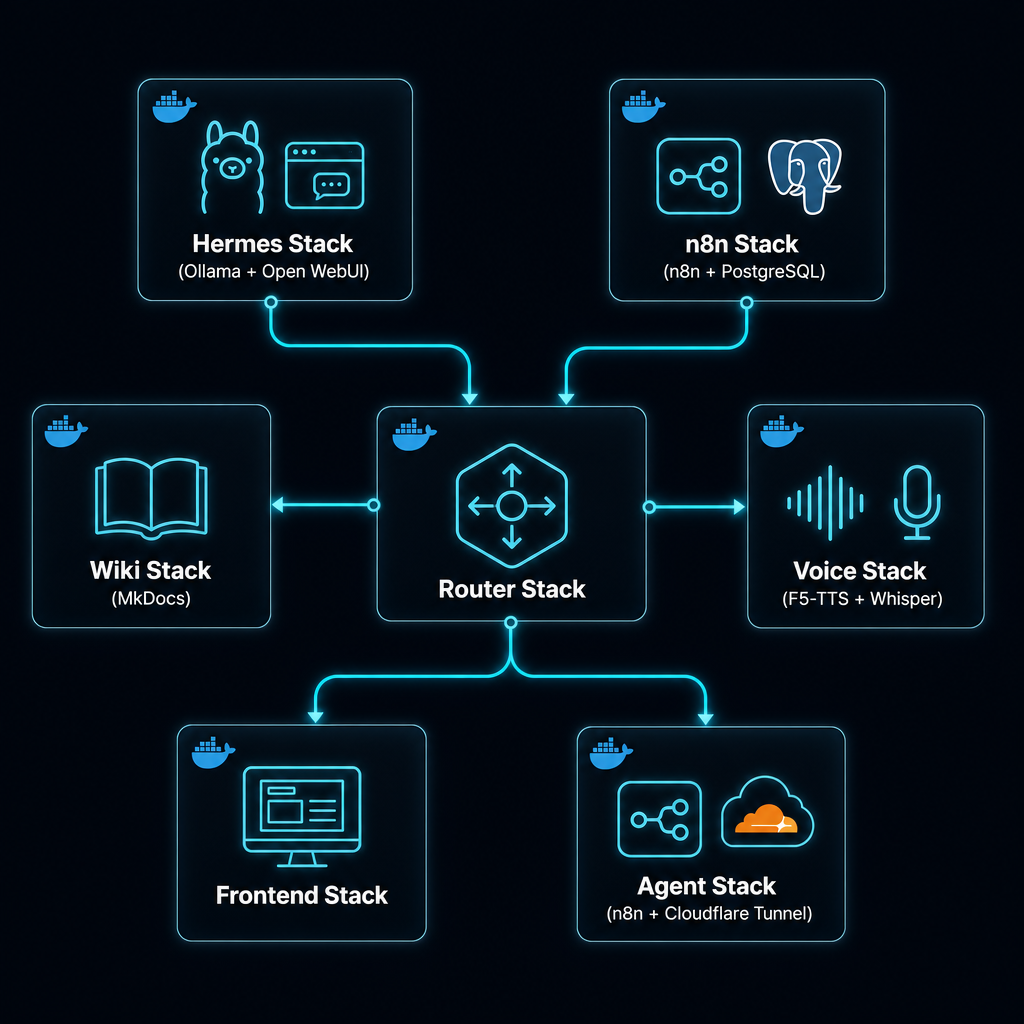
Claude Code Integration + Automation Stack
We integrate Claude Code via the CLI and share a single CLAUDE.md — which enforces our language rules, security protocols, and skill definitions across every tool. That means the Coder can switch freely between Hermes agent mode and Claude Code CLI mode — same rules, same constraints.
Our automation layer runs on:
- n8n — 10 active workflows for monitoring, alerts, and data pipelines
- Docker — 7 compose stacks managing 12 containers
- Cloudflare Tunnel — exposes
wwailab.comto external webhooks - Cron — 6 schedules handling routine tasks
One example: our market-monitoring pipeline scans OzBargain and Stereonet for specific deal patterns, triggers an alert via n8n, then pushes it to Telegram — with zero human intervention.
Automated Agent Team Workflows
This is where the multi-agent system really earns its keep. A single high-level request can trigger a coordinated workflow spanning multiple profiles.
Real case: generating a technical white paper.
- 1Manager receives the request → decomposes it into research, writing, diagramming, and publishing
- 2Writer researches the topic (e.g. EAP-TLS authentication) → produces structured markdown
- 3Designer builds the architecture and flow diagrams
- 4Coder assembles the final output — website, PDF, or video presentation
- 5Wiki Agent archives the session and creates cross-links in the knowledge base
The Manager tracks dependencies at each stage and merges results. Once the initial request is sent, no human needs to step into the flow.
In action: EAP-TLS Video Presentation | WhatsApp Voice Site
BAU — Day-to-Day Operations
A lab running 24/7 has to take care of itself. Our operations layer handles:
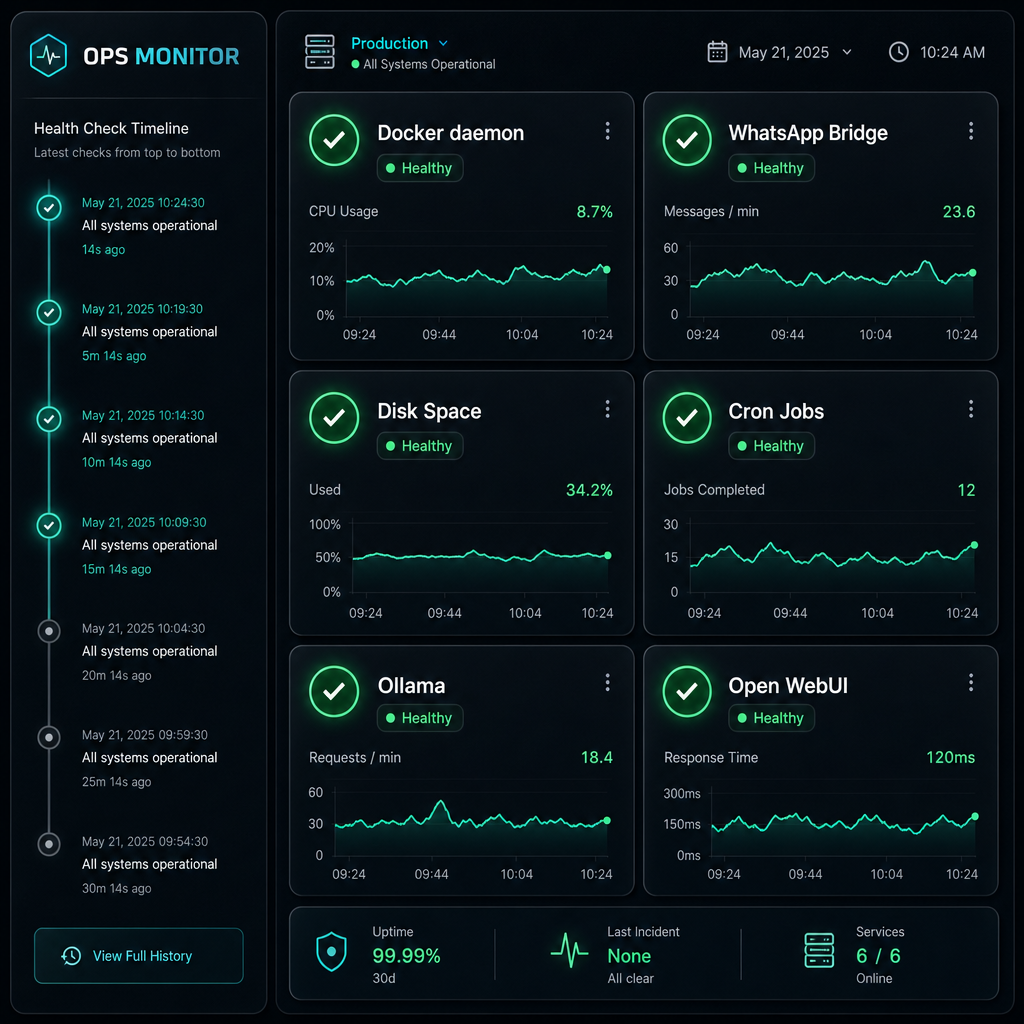
- Health checks — every 15 minutes: Docker daemon status, WhatsApp bridge connection, disk space, cron job liveness
- Backups — daily automated: core config (3 rolling versions), large files (2 rolling versions), synced to Google Drive (~2.4 GB total)
- Disaster recovery — every component has detailed recovery documentation (see system-migration-guide)
- Monitoring — a docker-watchdog cron job automatically restarts failed containers
Self-healing isn't a feature. When you run this many moving parts, it's a requirement. The system doesn't wait for someone to notice it's down before it acts.
Reference: System migration guide — the complete disaster-recovery handbook.
Recent Writing
